Is my query done yet? Tips for Optimizing SQL queries
I was recently was up until about 3 am on a Friday night, waiting for a SQL query to run. It was a fairly simple statement, but the base table had about 400 million records, so I was expecting a long run time. Sadly, the query crashed after 9 hours. No results.
This sleepless night got me thinking - there must have been a better way! So here, I will summarize how to optimize your SQL algorithm.
For each of these scenarios, I’ll be using this little dummy dataset:
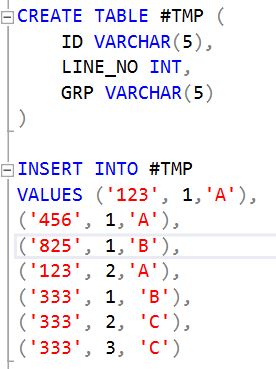
1) Index large tables
Any time you query a table in SQL, SQL needs to search through records to find what it’s looking for. Searching through records is much faster when the table is indexed, especially when your table is large (over 1 million rows).

As a best practice, index your table on fields that are:
common identifiers (record ID, dates, etc.)
fields that will be used to join to other tables
2) Filter before you aggregate
This was crux of my problem on my late Friday night! I was grouping a table by year, and getting a distinct count of ids in each group. This involved puting the DISTINCT keyword inside COUNT(), which is known to be very slow in SQL (see this post for more info).
Use subqueries to get filtered datasets, or distinct values before you join/aggregate.

3) Avoid writing large tables to the temp database
My example table is very small, and doesn’t pose any trouble as a temp table. However, I have noticed that writing a temp table that is millions of rows is significantly slower than writing a static table of the same size.